Do you ever get a niggling feeling, like someone is watching you?
Conversations overheard, habits recorded, footsteps followed slowly down lonely streets - a constant heavy feeling, like someone or something is looking over your shoulder.
In the physical world, these occurrences would make the hair on your arms stand on end, but what if this presence wasn’t in the physical world but rather an omnipresent shadow on your digital devices?
In the era of big data, we are all being followed; however, whether this practice is as insidious as a real-life stalker is still very much undecided. At the heart of this debate is the ethics of big data.
Algorithmic bias & inequalities
Reducing these harms requires diverse and representative training datasets, ongoing auditing processes, and transparent governance frameworks that ensure models are held accountable for their impact.

Source: TrustArc
The evolution of big data
To understand how big data has evolved to have its current-day reputation for surveillance, we must first understand what big data is and how we have come to rely so heavily upon the digital devices that generate it.
Big data is defined as a large volume of data - both structured, for example, names, addresses, credit card numbers, geolocation, etc., and unstructured, for example, photos, audio, video, social media posts, etc.)
In 2001, Gartner analyst, Doug Laney, introduced the concept of the 3Vs as a way to help conceptualise big data; they are:
- Volume - the vast amount of big data.
- Variety - the diversity and range of types and formats of big data available.
- Velocity - the great speed at which big data is generated, received, stored, managed and processed.
Over the years, as the field of big data evolved to become more user-focused, the 3Vs model also evolved to include three further Vs:
- Veracity - the quality and accuracy of the data being processed and analysed; high veracity data contains a lot of meaningful or 'true' information that can be used for analysis, while low veracity data contains little-to-no meaningful information - otherwise referred to as noise.
- Value - the level of valuable insights that can be garnered from the data to improve customer experience and business decisions.
- Variability - the extent and the speed at which data is changing.
Big data has facilitated the rise in new technologies like IoT (internet of things) devices and AI (artificial intelligence), which generate, analyse and use data at a faster, larger and more complex scale than most humans could ever comprehend.
If used correctly, big data has the potential to shape our futures for the better or, if wrongly implemented, negatively impact the lives of millions - this is why we require big data ethics.
Big data ethics: the big data journey
2.5 quintillion data bytes are generated globally each day. The journey your data goes on from creation to completion looks roughly like this:
- Non-existence
- User generates data
- Data collected via a storage system
- Data processed for analysis
- Action is taken (by a company or institution) based on analysis findings

Source: Internet Live Stats
The process of an individual generating data is known as user interaction because we interact with a system that collects our data. Data collection can be classified as active (when a user directly sends their data to a storage system, i.e. data collected by an app that has been explicitly consented to) or passive (when a citizens data is collected by a third party and input into an online storage system, i.e. hospital medical records).
Giving over your information to an organisation, a.k.a. data transfer, is where we begin to see the waters of big data ethics muddy somewhat.
Data transfers occur in two ways:
- Conscious data transfer: a user is informed of data transfer in a timely and straightforward manner; they are aware that their data is being collected and stored.
- Non-conscious data transfer: the user is not informed of data transfer in a timely and clear manner; they are unaware that their data is being collected and stored.
In other words, your data can be collected online whether you know about it in real-time or not, and this, right here, is why we get that stalker-like feeling as if we’re being followed around on the internet.
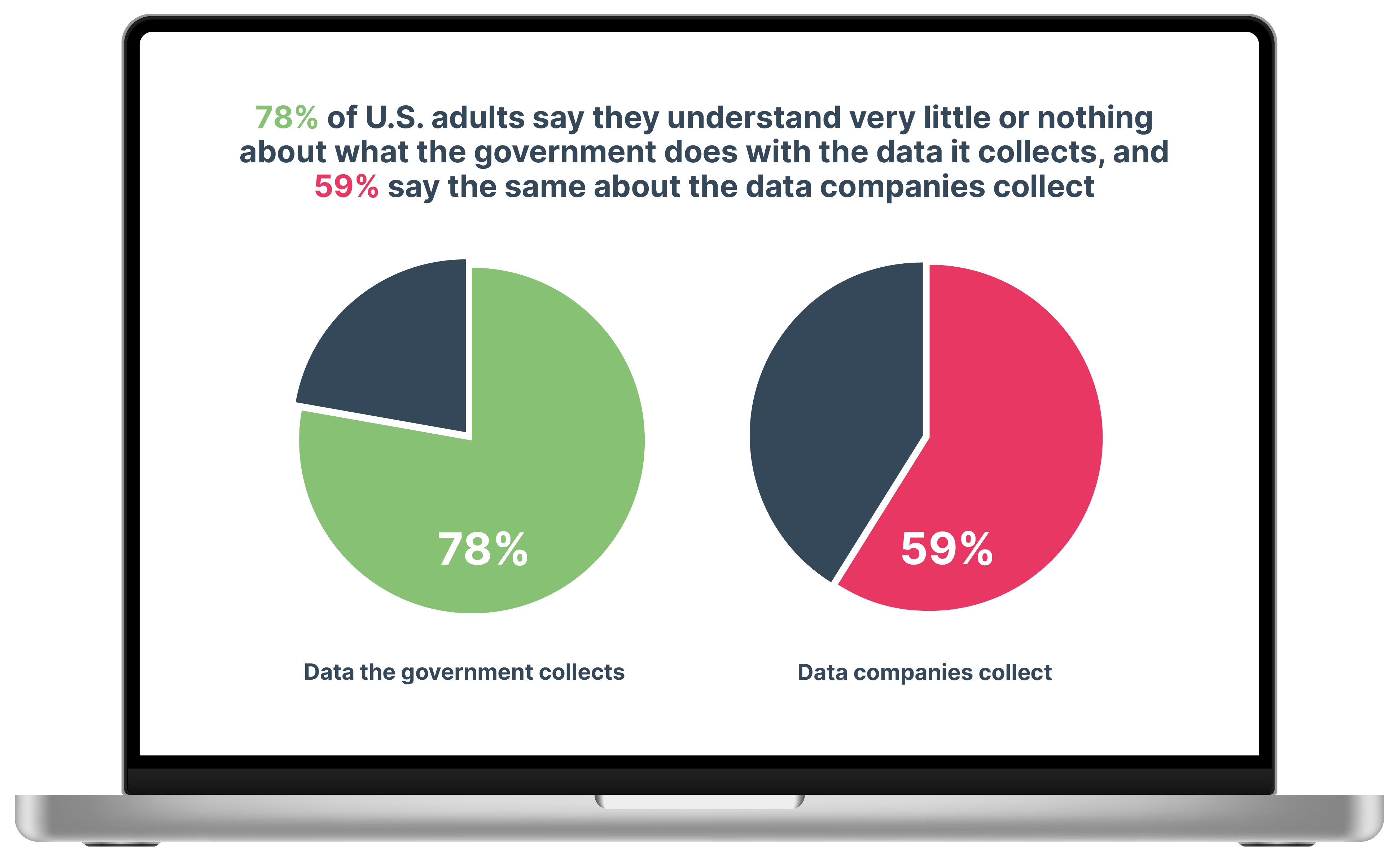
Source: Pew Research Centre
There has been a significant push-back against covert big data collection, which impacted how companies, institutions, and marketers collect and utilise consumer data. The focus of all of these legislative and regulatory efforts is based on the study of big data ethics.
What is big data ethics?
Much research has gone into the field of big data ethics in the past decade as academics and business leaders alike attempt to grapple with public push-back on the use of big data.
The field of big data ethics itself is defined as outlining, defending and recommending concepts of right and wrong practice when it comes to the use of data, with particular emphasis on personal data. Big data ethics aims to create an ethical and moral code of conduct for data use.
There are five main areas of concern in big data ethics that outline the potential for immoral use of data:
-
Informed consent
To consent means that you give uncoerced permission for something to happen to you.
Informed consent is the most careful, respectful and ethical form of consent. It requires the data collector to make a significant effort to give participants a reasonable and accurate understanding of how their data will be used.
In the past, informed consent for data collection was typically taken for participation in a single study. Big data makes this form of consent impossible as the entire purpose of big data studies, mining and analytics is to reveal patterns and trends between data points that were previously inconceivable. In this way, consent cannot possibly be ‘informed’ as neither the data collector nor the study participant can reasonably know or understand what will be garnered from the data or how it will be used.
Revisions to the standard of informed consent have been introduced. The first is known as ‘broad consent’, which pre-authorises secondary uses of data. The second is ‘tiered consent’, which gives consent to specific secondary uses of data, for example, for cancer research but not for genomic research. Some argue that these newer forms of consent are a watering down of the concept and leave users open to unethical practices.
Further issues arise when potentially ‘unwilling’ or uninformed data subjects have their information scraped from social media platforms. Social media Terms of Service contracts commonly include the right to collection, aggregation and analysis of such data. However, Ofcom found that 65% of internet users usually accept terms and conditions without reading them. So, it’s not unreasonable to assume that many end-users may not understand the full extent of the data usage, which increasingly extends beyond digital advertising and into social science research.
2. Privacy
The ethics of privacy involve many different concepts such as liberty, autonomy, security, and in a more modern sense, data protection and data exposure.
You can understand the concept of big data privacy by breaking it down into three categories:
-
- The condition of privacy
- The right to privacy
- The loss of privacy and invasion
The scale and velocity of big data pose a serious concern as many traditional privacy processes cannot protect sensitive data, which has led to an exponential increase in cybercrime and data leaks.
One example of a significant data leak that caused a loss of privacy to over 200 million internet users happened in January 2021. A rising Chinese social media site called Sociallarks suffered a breach due to a series of data protection errors that included an unsecured ElasticSearch database. A hacker was able to access and scrape the database which stored:
- Names
- Phone numbers
- Email addresses
- Profile descriptions
- Follower and engagement data
- Locations
- LinkedIn profile links
- Connected social media account login names
Corporate responsibilities in data security
• Implement strong encryption protocols
• Conduct routine security audits
• Train employees in cybersecurity best practices
• Maintain real-time breach detection systems
• Provide rapid and transparent breach notification
A further concern is the growing analytical power of big data, i.e. how this can impact privacy when personal information from various digital platforms can be mined to create a full picture of a person without their explicit consent. For example, if someone applies for a job, information can be gained about them via their digital data footprint to identify political leanings, sexual orientation, social life, etc. All of this data could be used as a reason to reject an employment application even though the information was not offered up for judgement by the applicant.
Data collection & surveillance ethics

Source: The Financial Times
3. Ownership
When we talk about ownership in big data terms, we steer away from the traditional or legal understanding of the word as the exclusive right to use, possess, and dispose of property. Rather, in this context, ownership refers to the redistribution of data, the modification of data, and the ability to benefit from data innovations.
In the past, legislators have ruled that as data is not property or a commodity, it, therefore, cannot be stolen - this belief offers little protection or compensation to internet users and consumers who provide valuable information to companies without personal benefit.
We can split ownership of data into two categories:
- The right to control data - edit, manage, share and delete data
- The right to benefit from data - profit from the use or sale of data
Contrary to common belief, those who generate data, for example, Facebook users, do not automatically own the data. Some even argue that the data we provide to use ‘free’ online platforms is in fact a payment for that platform. But big data is big money in today’s world. Many internet users feel that the current balance is tilted against them when it comes to ownership of data and the transparency of companies who use and profit from the data we share.

Source: The Drum
In recent years, the idea of monetising personal data has gained traction; the ideology aims to give ownership of data back to the user and balance the market by allowing users to sell their data legally. This is a highly contentious field of legislation, and some argue that to designate data as a commodity is to lose our autonomy and freedoms.
Ethical frameworks: Ownership & consent
4. Algorithm bias and objectivity
Algorithms are designed by humans, the data sets they study are selected and prepared by humans, and humans have bias.
So far, there is significant evidence to suggest that human prejudices are infecting technology and algorithms, and negatively impacting the lives and freedoms of humans. Particularly those who exist within the minorities of our societies.
The so-called “coded bias” has been identified in such high-profile cases as MIT lab researcher Joy Buolamwini’s discovery of racial skin-type bias from commercial artificial intelligence systems created by giant US companies. Buolamwini found that the software had been trained on datasets of 77% male pictures and more than 83% white-skinned pictures. These biased datasets created a situation wherein the program fails to recognise white male faces at an error rate of only 0.8%, whereas dark-skinned female faces are detected at an error rate of 20% in one case and 34% in the other two. These biases extend beyond racial and gendered lines and into the issues of criminal profiling, poverty and housing.
Algorithm biases have become such an ingrained part of everyday life that they have also been documented as impacting our personal psyches and thought processes. The phenomenon occurs when we perceive our reality to be a reflection of what we see online. However, what we view is often a tailored reality created by algorithms and personalised using our previous viewing habits. The algorithm shows us content that we are most likely to enjoy or agree with and discards the rest. When filter bubbles like this exist they create echo chambers and, in extreme cases, can lead to radicalisation, sectarianism and social isolation.
Autonomy & freedom: The impact of predictive analytics

Personalized healthcare & genetic data ethics
Data justice & fairness principles
Predictive policing ethics
The big data divide seeks to define the current state of data access; the understanding and mining capabilities of big data is isolated within the hands of a few major corporations. These divides create ‘haves’ and ‘have nots’ in big data and exclude those who lack the necessary financial, educational and technological resources to access and analyse big datasets.
Tim Berners-Lee has argued that the big data divide separates individuals from data that could be highly valuable to their wellbeing. And despite the growing industry of applications that use data to enhance our lives in terms of health, finance, etc., there is currently no way for individuals to mine their own data or connect potential data silos missed by commercial software. Again, we face the ethical problem of who owns the data we generate; if our data is not ours to modify, analyse and benefit from on our own terms, then indeed we do not own it.
The data divide creates further problems when we consider algorithm biases that place individuals in categories based on a culmination of data that individuals themselves cannot access. For example, profiling software can mark a person as a high-risk potential for committing criminal activity, causing them to be legally stop-and-searched by authorities or even denied housing in certain areas. The big data divide means that the ‘data poor’ cannot understand the data or methods used to make these decisions about them and their lives.
Black box AI & the need for transparency
GDPR Data Processing Agreement: influence on digital
The General Data Protection Regulation (GDPR) was introduced in Europe in 2016 as a direct response to these big data ethics concerns. The regulation followed a pledge from the EU Commission to “protect[ing] and promot[ing] citizen rights, to make the EU’s online environment the safest in the world.”
The full-text GDPR contains 99 articles that set out individuals’ rights and outline the standard practises for businesses that record, store, or manage personal data. The rights are outlined by the ICO as follows:
- The right to be informed
- The right of access
- The right to rectification
- The right to erasure
- The right to restrict processing
- The right to data portability
- The right to object
- Rights in relation to automated decision making and profiling.
The regulation also introduced rules for businesses using third parties to process customer data under article 28. Under the new law, if your company is subject to GDPR, you must have a written data processing agreement with third-party data processors, for example, your CRM provider.
The regulations have had a major impact on how companies interact with personal data and have had a significant impact on digital marketing. There are three key areas of digital marketing that GDPR has influenced:
- Legal basis for processing - GDPR laid out several grounds for data processing (consent*, contract, legal obligation, vital interests, public task, legitimate interest).
- Getting consent* - Most marketers now rely on consent as their basis for processing; the law requires consent to be ‘granular, affirmative and freely given’, meaning old practices like pre-ticked opt-in boxes are no longer acceptable.
- Opting out - Consent must be freely given and easily revoked during your relationship with an individual and their data - it is now standard practice to include an ‘unsubscribe’ button in all direct marketing to ensure GDPR compliance.
Big data ethics is a complex and constantly evolving field. At its core, however, is the aim to ensure that all internet users have their rights protected online. The push to get businesses up to speed with data protection was a hard road and its influence on digital marketing can’t be ignored.
For some, the change was seen as a hindrance to their ability to do their job with many existing tactics used for lead generation, email marketing and targeted advertising having to be adapted.
The thing is, customer-centricity (which we should all be aiming for) is all about creating the best experience possible and adhering to GDPR and big data ethics standards have actually improved customer satisfaction rates for many marketers.
Get started on your free trial today and see how Hurree can help you transform your company reporting to improve your sales and marketing output 💌 Don't hesitate to get in touch via contact@hurree.co if you have any inquiries - we’re happy to chat!


Share this
[Infographic] Big Data Ethics

[Infographic] Explain The 3 V's of Big Data
